2.3 Scraping: Messy and Mangled
If you are reading this textbook, at some point in your career, you are likely to want or need data which exists on the web. You have looked for downloadable sources and Google searched for an API, but alas, no luck. The last resort for importing data into R is web scraping. Web scraping is a technique for harvesting data which is portrayed on the web and exists in hypertext markup language (HTML), the language of web browser documents.
2.3.1 Scraping vs APIs
The benefit of using an API are clean data. For example, we can traverse the result to find the latest NFL events.
[1] "Atlanta Falcons @ Dallas Cowboys"
[2] "Buffalo Bills @ New York Jets"
[3] "Cleveland Browns @ New England Patriots"
[4] "Detroit Lions @ Pittsburgh Steelers"
[5] "Jacksonville Jaguars @ Indianapolis Colts"
[6] "New Orleans Saints @ Tennessee Titans" With more digging, we can find which teams are playing at home.
[[1]]
id name home
1 9420754-11904234 Dallas Cowboys TRUE
2 9420754-11904242 Atlanta Falcons FALSE
[[2]]
id name home
1 9420740-11904241 New York Jets TRUE
2 9420740-11904215 Buffalo Bills FALSE
[[3]]
id name home
1 9420738-11852810 New England Patriots TRUE
2 9420738-11904219 Cleveland Browns FALSE
[[4]]
id name home
1 9420743-11904223 Pittsburgh Steelers TRUE
2 9420743-11904244 Detroit Lions FALSE
[[5]]
id name home
1 9420734-11904232 Indianapolis Colts TRUE
2 9420734-11904220 Jacksonville Jaguars FALSE
[[6]]
id name home
1 9420742-11904229 Tennessee Titans TRUE
2 9420742-11904221 New Orleans Saints FALSEWe can also find the current line of each of these games. Here, I have created a function called get_bovada_lines() which traverses this complicated (yet clean) JSON object using methods explored in Chapter 3 and combines the information together into a rectangular data set.
While traversing these sometimes complicated lists may seem intimidating, with practice, working with data from an API will be made easier after discussing mapping functions in Chapter 3 which are useful for traversing complicated lists. Hopefully, after the scraping section, you will find working with APIs like a walk in the park compared to scraping data directly from the web.
2.3.2 Lessons Learned from Scraping
Scraping is a necessary evil that requires patience. While some tasks may prove easy, you will quickly find others seem insurmountable. In this section, we will outline a few tips to help you become a web scraper.
Brainstorm! Before jumping into your scraping project, ask yourself what data do I need and where can I find it? If you discover you need data from various sources, what is the unique identifier, the link which ties these data together? Taking the time to explore different websites can save you a vast amount of time in the long run. As a general rule, simplistic looking websites are generally easier to scrape and often contain the same information as more complicated websites with several bells and whistles.
Start small! Sometimes a scraping task can feel daunting, but it is important to view your project as a war, splitting it up into small battles. If you are interested in the racial demographics of each of the United States, consider how you can first scrape this information for one state. In this process, don’t forget tip 1!
Hyperlinks are your friend! They can lead to websites with more detailed information or serve as the unique identifier you need between different data sources. Sometimes you won’t even need to scrape the hyperlinks to navigate between webpages, making minor adjustments to the web address will sometimes do.
Data is everywhere! Text color, font, or highlighting may serve as valuable data that you need. If these features exist on the webpage, then they exist within the HTML code which generated the document. Sometimes these features are well hidden or even inaccessible, leading to the last and final tip.
Ready your search engine! Just like coding in
Ris an art, web developing is an art. When asking distinct developers to create the same website with the same functionality, the final result may be similar but the underlying HTML code could be drastically different. Why does this matter? You will run into an issue that hasn’t been addressed in this text. Thankfully, if you’ve run into an issue, someone else probably has too. We cannot recommend websites like Stack Overflow enough.
2.3.3 Tools for Scraping
Before we can scrape information from a webpage, we need a bit of background on how this information is stored and presented. The goal of this subsection is to briefly introduce the languange of the web, hypertext markup language (HTML). When we talk about scraping the web, what we really mean is gathering bits of information from the HTML code used to build a webpage. Like R code, HTML can be overwhelming. The goal is not to teach HTML but to introduce its components, so you have a much more intuitive sense of what we are doing when we scrape the web.
2.3.3.1 Hypertext Markup Language (HTML)
Web sites are written in hypertext markup language. All contents that are displayed on a web page are structured through HTML with the help of HTML elements. HTML elements consist of a tag and contents. The tag defines how the web browser should format and display the content. Aptly, the content is what should be displayed.
For example, if we wished to format text as a paragraph within the web document, then we could use the paragraph tag, <p>, to indicate the beginning of a paragraph. After opening a tag, we then specify the content to display before closing the tag. A complete paragraph may read:
<p> This is the paragraph you want to scrape. </p>
Attributes are optional parameters which provide additional information about the element in which the attribute is included. For example, within the paragraph tag, you can define a class attribute which formats the text in a specific way, such as bolding, coloring, or aligning the text. To extend our example, the element may read:
<p class = "fancy"> This is the paragraph you want to scrape which has been formatted in a fancy script. </p>
The type of attribute, being class, is the attribute name, whereas the quantity assigned to the attribute, being fancy, is the attribute value. The general decomposition of an HTML element is characterized by the following figure:

Figure 2.1: the lingo of an HTML element
The class attribute is a flexible one. Many web developers use the class attribute to point to a class name in a style sheet or to access and manipulate elements with the specific class name with a JavaScript. For more information of the class attribute, see this link. For more information on cascading style sheets which are used to decorate HTML pages, see this link.
Any feedback for this section? Click here
2.3.3.2 Selector Gadgets
While all web pages are composed of HTML elements, the elements themselves can be structured in complicated ways. Elements are often nested inside one another or make use of elements in other documents. These complicated structures can make scraping data difficult. Thankfully, we can circumvent exploring these complicated structures with the help of selector gadgets.
A selector gadget allows you to determine what css selector you need to extract the information desired from a webpage. These JavaScript bookmarklets allow you to determine where the information you desire belongs within the complicated structure of elements that makeup a webpage. To follow along in Chapter 3, you will need to download one of these gadgets from this link. If you use Google Chrome, you can download the bookmark extension directly from this link.
If the selector gadget fails us, we can always view the structure of the elements directly by viewing the page source. This can be done by right-clicking on the webpage and selecting ‘View Page Source’. For Google Chrome, you can also use the keyboard shortcut ‘CTRL-U’.
2.3.4 Scraping NFL Data
In Chapter 2.2, we gathered some betting data pertaining to the NFL through a web-API. We may wish to supplement these betting data with data pertaining to NFL teams, players, or even playing conditions. The goal in this subsection is to introduce you to scraping by heeding the advice given in the Chapter 2.3.2. Further examples are given in the supplemental material.
Following our own advice, let’s brainstorm. When you think of NFL data, you probably think of NFL.com or ESPN. These sites obviously have reliable data, but the webpages are pretty involved. While the filters, dropdown menus, and graphics lend great experiences for web browsers, they create headaches for web scrapers. After further digging, we will explore Pro Football Reference, a reliable archive for football statistics (with a reasonably simple webpage). This is an exhaustive source which boasts team statistics, player statistics, and playing conditions for various seasons. Let’s now start small by focusing on team statistics, but further, let’s limit our scope to the 2020 Denver Broncos. Notice, there are hyperlinks for each player documented in any of the categories, as well hyperlinks for each game’s boxscore where there is information about playing conditions and outcomes. Hence, we have a common thread between team statistics, players, and boxscores. If, for example, we chose to scrape team statistics from one website and player statistics from another website, we may have to worry about a unique identifier (being team) if the websites have different naming conventions.
2.3.4.1 HTML Tables: Team Statistics
We’ll start with the team statistics for the 2020 Denver Broncos which can be found in a table entitled ‘Team Stats and Rankings’. We’ll need to figure in which element or node the table lives within the underlying HTML. To do this, we will utilize the CSS selector gadget. If we highlight over and click the table with the selector gadget, we will see that the desired table lives in an element called ‘#team_stats’.
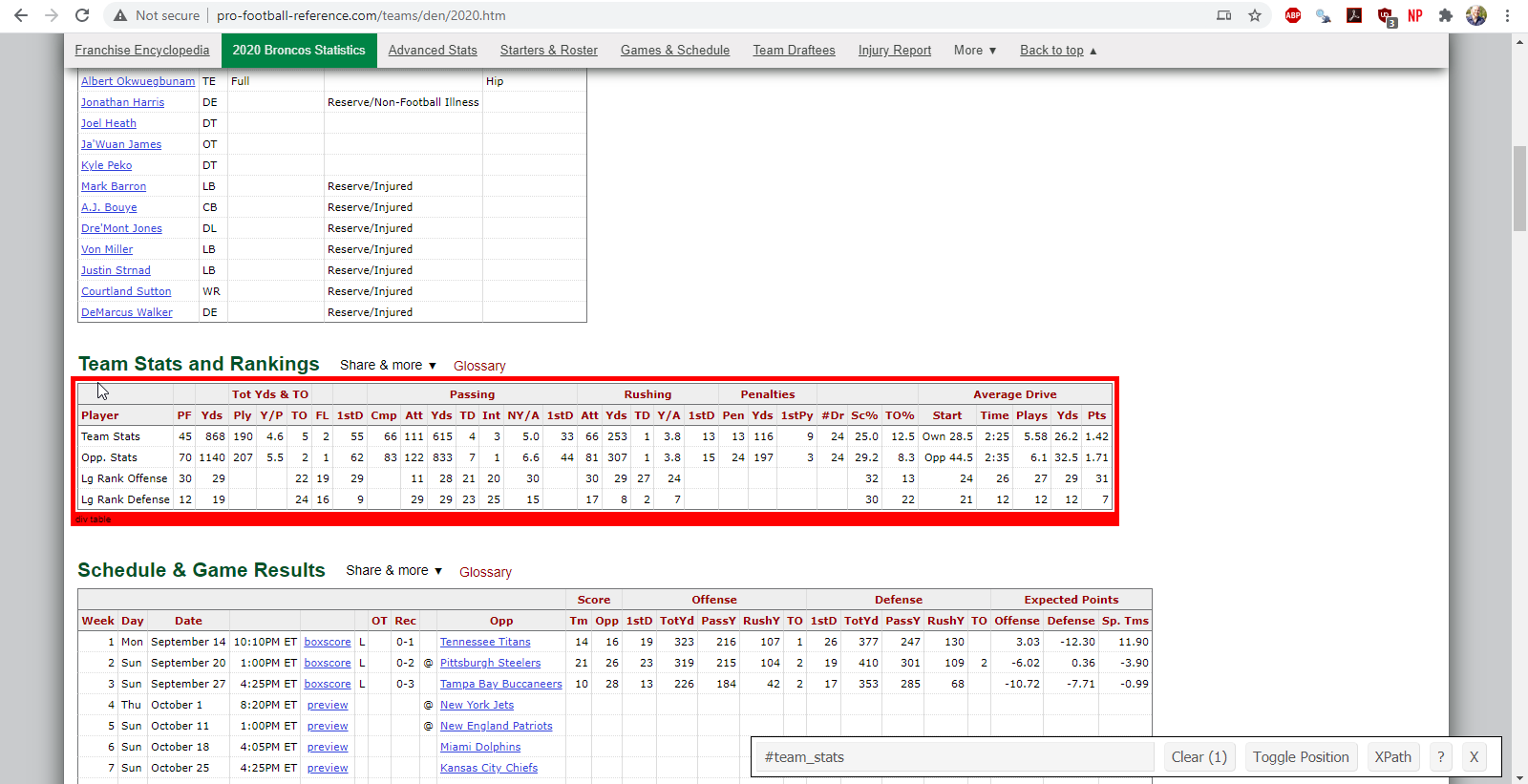
Figure 2.2: finding the team statistics element using the selector gadget
Alternatively, we could view the page source and search for the table name. I’ve highlighted the information identified by the selector gadget with the cursor.
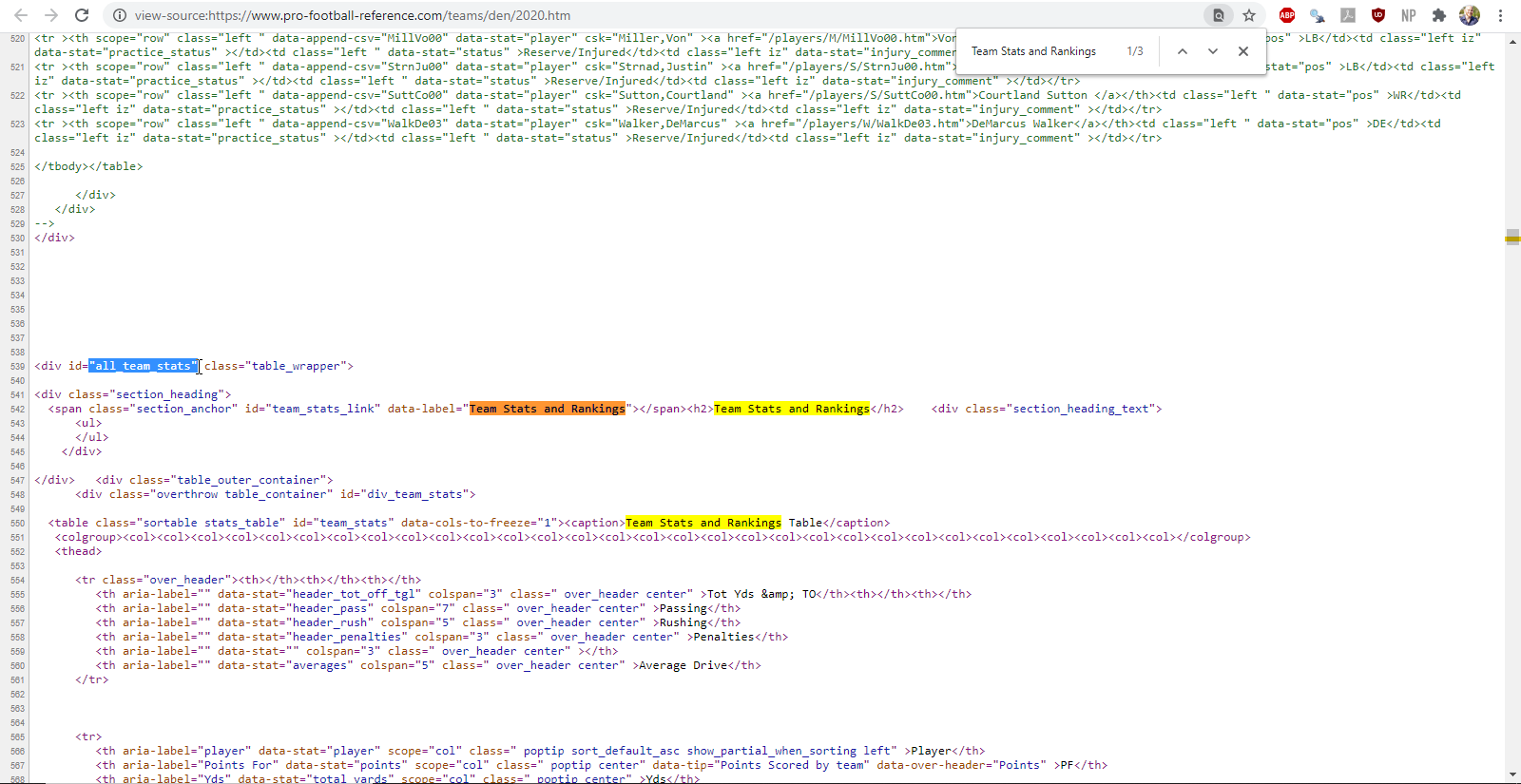
Figure 2.3: finding the team statistics element using the page source
While the selector gadget is always a great first option, it is not always reliable. There are instances when the selector gadget identifies a node that is hidden or inaccessible without JavaScript. In these situations, it is best view the page source directly for more guidance on how to proceed. Practice with both the selector gadget and the page source.
Once we have found the name of the element containing the desired data, we can utilize the rvest package to scrape the table. The general process for scraping an HTML table is
- Read the HTML identified by the web address.
- Isolate the node containing the data we desire.
- Parse the HTML table.
- Take a look at the data to ensure the columns are appropriate labels.
library(rvest)
library(janitor)
pfr_url <- "https://www.pro-football-reference.com"
broncos_url <- str_c(pfr_url, '/teams/den/2020.htm')
broncos_url %>%
# read the HTML
read_html(.) %>%
# isolate the node containing the HTML table
html_node(., css = '#team_conversions') %>%
# parse the html table
html_table(.) %>%
# make the first row of the table column headers and clean up column names
row_to_names(., row_number = 1) %>%
clean_names()While these data need cleaning up before they can be used in practice, we will defer these responsibilities to Chapter 3.
Take this time to scrape the ‘Team Conversions’ table on your own.
While it is exciting to scrape your first nuggets of data, we have just scratched the surface of web scraping. To be honest, it took some time to find data this easy to scrape. More often than not, difficulties arise. The HTML table you want may be commented out or hidden. Your data may not be in the form of a table, at all. For a more in-depth exposition of web scraping, see the supplemental materials.
Any feedback for this section? Click here